Latency vs Throughput
Pengertian
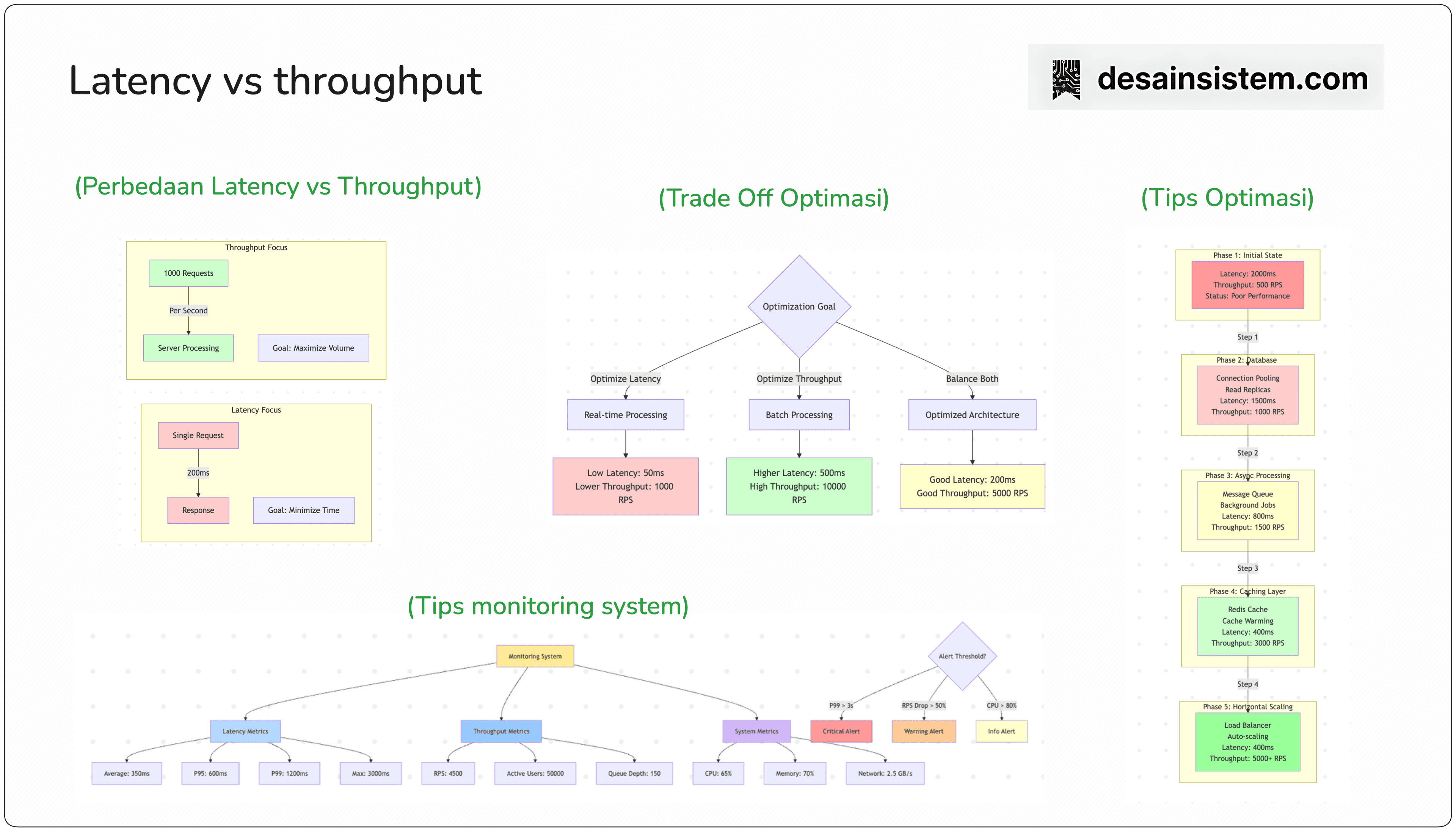
Dalam system design, Latency dan Throughput adalah dua metrik performa yang fundamental namun sering disalahpahami. Keduanya mengukur aspek berbeda dari performa sistem dan sering kali memiliki trade-off satu sama lain.
Latency (Latensi)
Latency adalah waktu yang dibutuhkan untuk menyelesaikan satu operasi atau request dari awal hingga akhir. Latency diukur dalam satuan waktu seperti milidetik (ms) atau detik.
Contoh Sederhana:
Waktu yang dibutuhkan dari user mengklik tombol "Submit" hingga menerima respons
Waktu round-trip dari client mengirim request hingga menerima response
Waktu query database dari eksekusi hingga mendapat hasil
Throughput
Throughput adalah jumlah operasi atau data yang dapat diproses sistem dalam periode waktu tertentu. Throughput diukur dalam satuan seperti requests per second (RPS), transactions per second (TPS), atau megabytes per second (MB/s).
Contoh Sederhana:
Jumlah transaksi yang dapat diproses per detik
Jumlah user yang dapat dilayani secara bersamaan
Bandwidth jaringan dalam MB/s

Perbedaan Mendasar
| Aspek | Latency | Throughput |
| Definisi | Waktu untuk 1 operasi | Jumlah operasi per waktu |
| Satuan | Milidetik, detik | RPS, TPS, MB/s |
| Fokus | Kecepatan respons | Kapasitas sistem |
| User Experience | Responsiveness | Kemampuan menangani beban |
| Contoh | Halaman load dalam 200ms | Server handle 10,000 RPS |
Mengapa Keduanya Penting?
User Experience
Latency rendah = Sistem terasa cepat dan responsif
Throughput tinggi = Sistem dapat melayani banyak user bersamaan
Business Impact
Latency: Amazon menemukan bahwa setiap 100ms peningkatan latency menurunkan sales 1%
Throughput: Sistem harus bisa handle traffic spike saat promo atau viral
Analogi Sederhana
Analogi Pipa Air:
Latency = Waktu yang dibutuhkan setetes air untuk mengalir dari ujung ke ujung pipa
Throughput = Jumlah total air yang bisa mengalir melalui pipa dalam satu menit
Analogi Jalan Tol:
Latency = Waktu tempuh dari Jakarta ke Surabaya (misalnya 10 jam)
Throughput = Jumlah mobil yang bisa melewati tol per jam (misalnya 1000 mobil/jam)
Anda bisa menambah throughput dengan menambah jalur (horizontal scaling), tapi latency tetap 10 jam karena ditentukan oleh jarak dan kecepatan maksimal.
Trade-off antara Latency dan Throughput

Seringkali, optimasi untuk satu metrik dapat mengorbankan metrik lainnya:
Skenario 1: Batch Processing
Meningkatkan Throughput, Mengorbankan Latency
Sistem mengumpulkan 100 request dan memprosesnya sekaligus
Throughput: Meningkat karena efisiensi batch processing
Latency: Meningkat karena request pertama harus menunggu 99 request lainnya
Skenario 2: Real-time Processing
Menurunkan Latency, Mengorbankan Throughput
Setiap request langsung diproses tanpa waiting
Latency: Sangat rendah, respons instant
Throughput: Lebih rendah karena overhead per-request processing
Faktor-faktor yang Mempengaruhi
Faktor yang Mempengaruhi Latency:
Network Latency
Jarak geografis antara client dan server
Kualitas koneksi internet
Jumlah network hops
Processing Time
Kompleksitas algoritma
Performa CPU
Efisiensi kode
I/O Operations
Kecepatan disk (SSD vs HDD)
Database query optimization
External API calls
Queueing Delays
Waktu tunggu dalam antrian
Load balancer overhead
Faktor yang Mempengaruhi Throughput:
Resource Capacity
Jumlah CPU cores
Memory available
Network bandwidth
Concurrency
Jumlah threads/workers
Connection pooling
Async processing
Bottlenecks
Database connections
Lock contention
Single-threaded components
System Architecture
Load balancing
Caching strategy
Horizontal scaling
Cara Mengukur Latency dan Throughput
Mengukur Latency
Metrik Penting:
Average Latency: Rata-rata waktu respons
Median Latency (P50): 50% request lebih cepat dari nilai ini
P95 Latency: 95% request lebih cepat dari nilai ini
P99 Latency: 99% request lebih cepat dari nilai ini
Maximum Latency: Worst case scenario
Mengapa Percentile Penting? Average bisa menyesatkan jika ada outliers. P95 dan P99 memberikan gambaran user experience yang lebih akurat.
Contoh:
100 requests dengan latency:
- 95 requests: 100ms
- 4 requests: 200ms
- 1 request: 5000ms (outlier)
Average: 247ms (misleading!)
P95: 200ms (lebih representatif)
P99: 5000ms (worst case)
Mengukur Throughput
Metrik Penting:
Requests Per Second (RPS)
Transactions Per Second (TPS)
Queries Per Second (QPS)
Concurrent Users
Tools untuk Measurement:
Apache Bench (ab)
JMeter
Gatling
K6
Locust

Studi Kasus: E-commerce Checkout
Situasi Awal
Sebuah e-commerce menghadapi masalah pada sistem checkout mereka:
Metrics:
Average Latency: 2 detik
P99 Latency: 8 detik
Throughput: 500 RPS
Peak Traffic: 2000 RPS (sistem overload)
Masalah:
Saat traffic normal (500 RPS), latency acceptable
Saat flash sale (2000 RPS), sistem melambat drastis
Banyak timeout dan failed transactions
User experience sangat buruk
Root Cause Analysis
Bottleneck yang Ditemukan:
Database Connection Pool terbatas (max 100 connections)
Payment Gateway API slow response (1-2 detik per call)
Stock Checking melakukan database query setiap request
No Caching untuk product data
Synchronous Processing untuk email dan notification
Strategi Optimasi
Optimasi 1: Connection Pool Management
Masalah: Database connection pool habis saat high traffic
Solusi:
Sebelum:
- Max connections: 100
- Timeout: 5 detik
- Wait time saat pool penuh: indefinite
Sesudah:
- Max connections: 500
- Timeout: 2 detik
- Connection reuse optimization
- Read replica untuk query heavy operations
Hasil:
Throughput meningkat dari 500 RPS → 1200 RPS
P99 latency turun dari 8s → 4s
Optimasi 2: Async Processing untuk Non-Critical Operations
Masalah: Email notification dan logging memperlambat response
Solusi:
Pisahkan critical path dan non-critical path
Gunakan message queue (RabbitMQ) untuk async processing
Email dan notification dikirim asynchronous
Critical Path (Synchronous):
Validate order
Check stock
Process payment
Create order record
Return success response
Non-Critical Path (Asynchronous):
Send email confirmation
Send SMS notification
Update analytics
Generate invoice PDF
Hasil:
Latency turun dari 2s → 800ms
Throughput meningkat karena freed up resources
User mendapat response lebih cepat
Optimasi 3: Caching Strategy
Masalah: Product data dan stock check selalu query database
Solusi:
Redis Cache untuk product data (TTL: 5 menit)
Local Cache untuk configuration data
Cache warming untuk produk populer
Cache aside pattern untuk cache misses
Implementation:
Check Stock Flow:
1. Check Redis cache first
2. If cache hit → return stock info (latency: 5ms)
3. If cache miss → query database (latency: 50ms)
4. Update cache
5. Return result
Before: Every request = 50ms database query
After: 95% requests = 5ms cache hit
Hasil:
Average latency turun dari 800ms → 400ms
Database load turun 80%
P95 latency turun dari 2s → 600ms
Optimasi 4: Payment Gateway Optimization
Masalah: Payment gateway API call memakan 1-2 detik
Solusi:
Connection Pooling ke payment gateway
Retry with exponential backoff
Circuit breaker pattern untuk handle gateway failures
Async payment verification untuk slow gateways
Strategi:
Before (Synchronous):
User Click Pay → Call Payment Gateway → Wait Response → Show Result
Total: 2000ms latency
After (Asynchronous):
User Click Pay → Create Pending Order → Return "Processing" → Background verify
Total: 200ms response latency
User gets real-time update via websocket
Hasil:
Initial response latency: 200ms
User experience: Lebih baik dengan real-time updates
Throughput: Meningkat karena tidak blocking
Optimasi 5: Load Balancing & Auto-scaling
Masalah: Single server tidak bisa handle peak traffic
Solusi:
Deploy multiple server instances
Nginx load balancer dengan least connection algorithm
Auto-scaling based on CPU dan RPS metrics
Health check dan automatic failover
Configuration:
Auto-scaling Rules:
- CPU > 70% → add 2 instances
- RPS > 1500 → add 2 instances
- CPU < 30% for 10 minutes → remove 1 instance
Load Balancing:
- Algorithm: Least connections
- Health check: Every 10 seconds
- Timeout: 30 seconds
- Max retries: 2
Hasil:
Throughput: 1200 RPS → 5000+ RPS
System dapat handle flash sale tanpa downtime
Cost efficient dengan auto-scaling down saat traffic normal
Hasil Akhir
Before Optimization:
Average Latency: 2000ms
P95 Latency: 5000ms
P99 Latency: 8000ms
Throughput: 500 RPS
Peak Capacity: 500 RPS (crash beyond this)
Success Rate: 85% during peak
Cost per Transaction: High (fixed infrastructure)
After Optimization:
Average Latency: 400ms (↓ 80%)
P95 Latency: 600ms (↓ 88%)
P99 Latency: 1200ms (↓ 85%)
Throughput: 5000+ RPS (↑ 900%)
Peak Capacity: 10,000+ RPS
Success Rate: 99.5% during peak
Cost per Transaction: ↓ 60% (auto-scaling)
Business Impact:
Conversion rate meningkat 45%
Cart abandonment turun 50%
Customer complaints turun 80%
Revenue during flash sale meningkat 3x
Infrastructure cost per transaction turun 60%
Best Practices
Untuk Optimasi Latency:
Minimize Network Hops
Gunakan CDN untuk static content
Deploy servers dekat dengan users (multi-region)
HTTP/2 atau HTTP/3 untuk multiplexing
Database Optimization
Add proper indexes
Query optimization
Use read replicas
Connection pooling
Caching
Cache frequently accessed data
Use appropriate TTL
Implement cache warming
Multi-layer caching (CDN, Redis, application)
Code Optimization
Remove unnecessary computations
Optimize algorithms
Reduce object allocations
Use async I/O
Async Processing
Move non-critical operations to background
Use message queues
Implement event-driven architecture
Untuk Optimasi Throughput:
Horizontal Scaling
Add more server instances
Implement load balancing
Design stateless applications
Use auto-scaling
Concurrency
Multi-threading
Async I/O
Non-blocking operations
Worker pools
Resource Management
Connection pooling
Thread pooling
Memory management
Efficient resource allocation
Batch Processing
Process multiple items together
Reduce per-item overhead
Optimize for throughput over latency (when appropriate)
Remove Bottlenecks
Identify and fix bottlenecks
Scale bottleneck components
Distribute load evenly
Monitor and optimize continuously
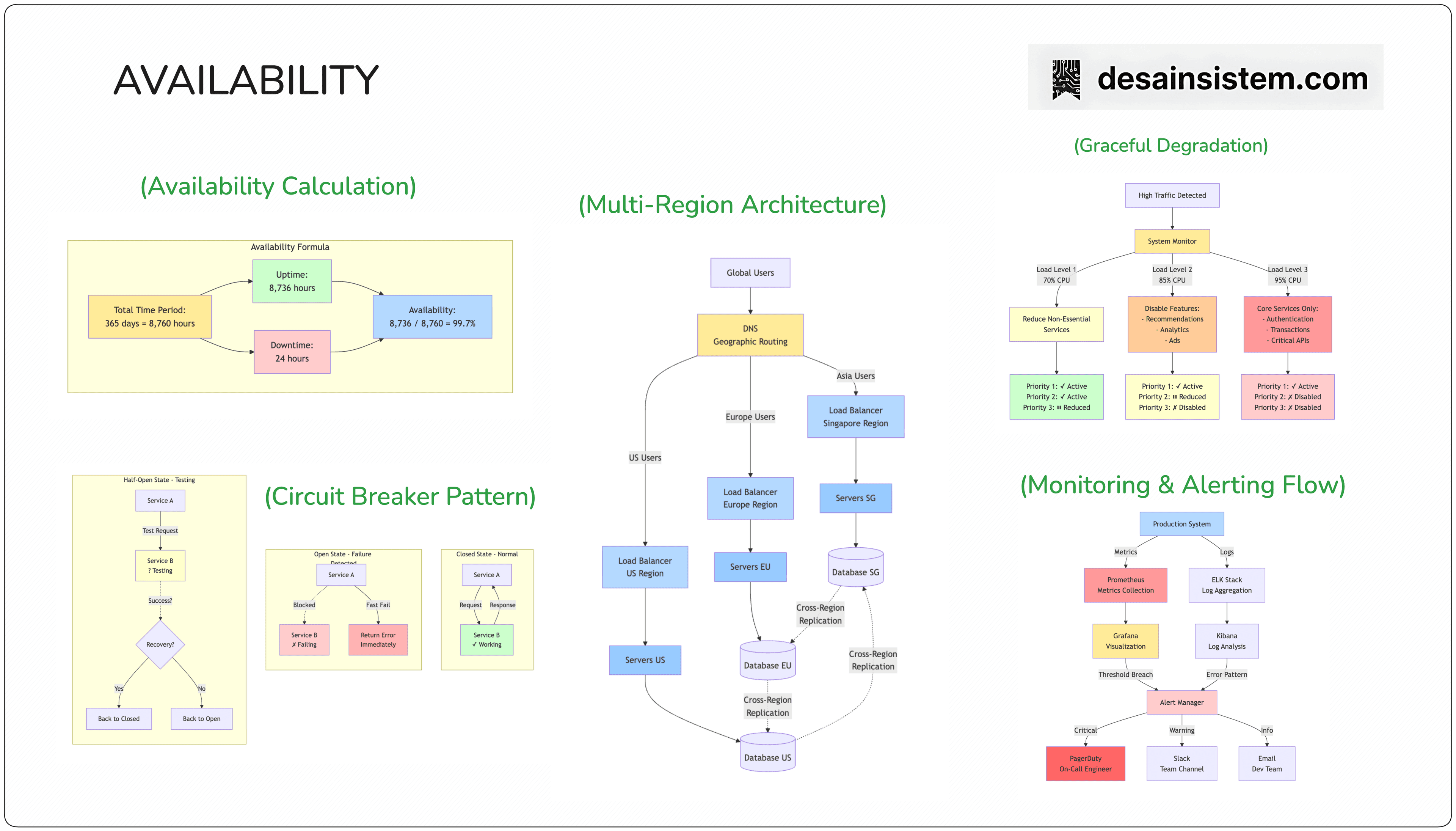
Monitoring dan Alerting
Metrics yang Harus Dimonitor:
Latency Metrics:
Average, P50, P95, P99, P99.9
Per endpoint/API
Per user segment
Per geographic region
Throughput Metrics:
Requests per second
Concurrent users
Active connections
Queue depth
System Metrics:
CPU usage
Memory usage
Network bandwidth
Disk I/O
Alerting Rules:
Critical Alerts:
- P99 latency > 3 seconds
- Error rate > 5%
- Throughput drop > 50%
- System availability < 99.5%
Warning Alerts:
- P95 latency > 1 second
- CPU usage > 80%
- Memory usage > 85%
- Queue depth > 1000
Kapan Fokus ke Latency vs Throughput?
Prioritas Latency:
User-facing applications: Web apps, mobile apps
Real-time systems: Trading platforms, gaming
Interactive services: Chat, video calls
APIs dengan SLA ketat: Payment, authentication
Prioritas Throughput:
Batch processing: Data analytics, ETL
Background jobs: Email sending, report generation
Log processing: Centralized logging
Data pipeline: Stream processing
Butuh Keduanya (Balanced):
E-commerce: Low latency checkout + high throughput untuk traffic
Social media: Fast feed loading + handle millions of users
Streaming: Low latency start + high bandwidth throughput
Search engines: Fast results + handle massive queries
Tools untuk Testing dan Monitoring
Load Testing Tools:
Apache Bench (ab) - Simple CLI tool
JMeter - Feature-rich GUI tool
Gatling - Scala-based, code as config
K6 - Modern, JavaScript-based
Locust - Python-based, distributed testing
Monitoring Tools:
Prometheus + Grafana - Metrics collection and visualization
New Relic - APM (Application Performance Monitoring)
Datadog - Full-stack monitoring
Elastic APM - Application performance monitoring
CloudWatch - AWS native monitoring
Profiling Tools:
Chrome DevTools - Frontend performance
Java Flight Recorder - JVM profiling
pprof - Go profiling
py-spy - Python profiling
perf - Linux system profiler
Kesimpulan
Latency dan Throughput adalah dua metrik fundamental dalam system design yang harus dipahami dan dioptimalkan secara berbeda:
Key Takeaways:
Latency = Speed per operation → Fokus pada responsiveness
Throughput = Volume per time → Fokus pada capacity
Trade-off exists → Optimasi satu bisa mengorbankan yang lain
Context matters → Pilih prioritas sesuai use case
Measure everything → Gunakan P95/P99, bukan hanya average
Continuous optimization → System perlu monitoring dan tuning berkelanjutan
Seperti yang terlihat dari studi kasus e-commerce, dengan strategi optimasi yang tepat, kita bisa meningkatkan kedua metrik sekaligus. Kuncinya adalah:
Identifikasi bottleneck dengan data
Prioritaskan optimasi yang berdampak besar
Implement caching strategis
Pisahkan critical dan non-critical path
Scale horizontal untuk throughput
Optimize code dan infrastructure untuk latency
Ingat: "You can't improve what you don't measure." Selalu mulai dengan monitoring dan measurement yang solid sebelum melakukan optimasi.