Availability
Pengertian
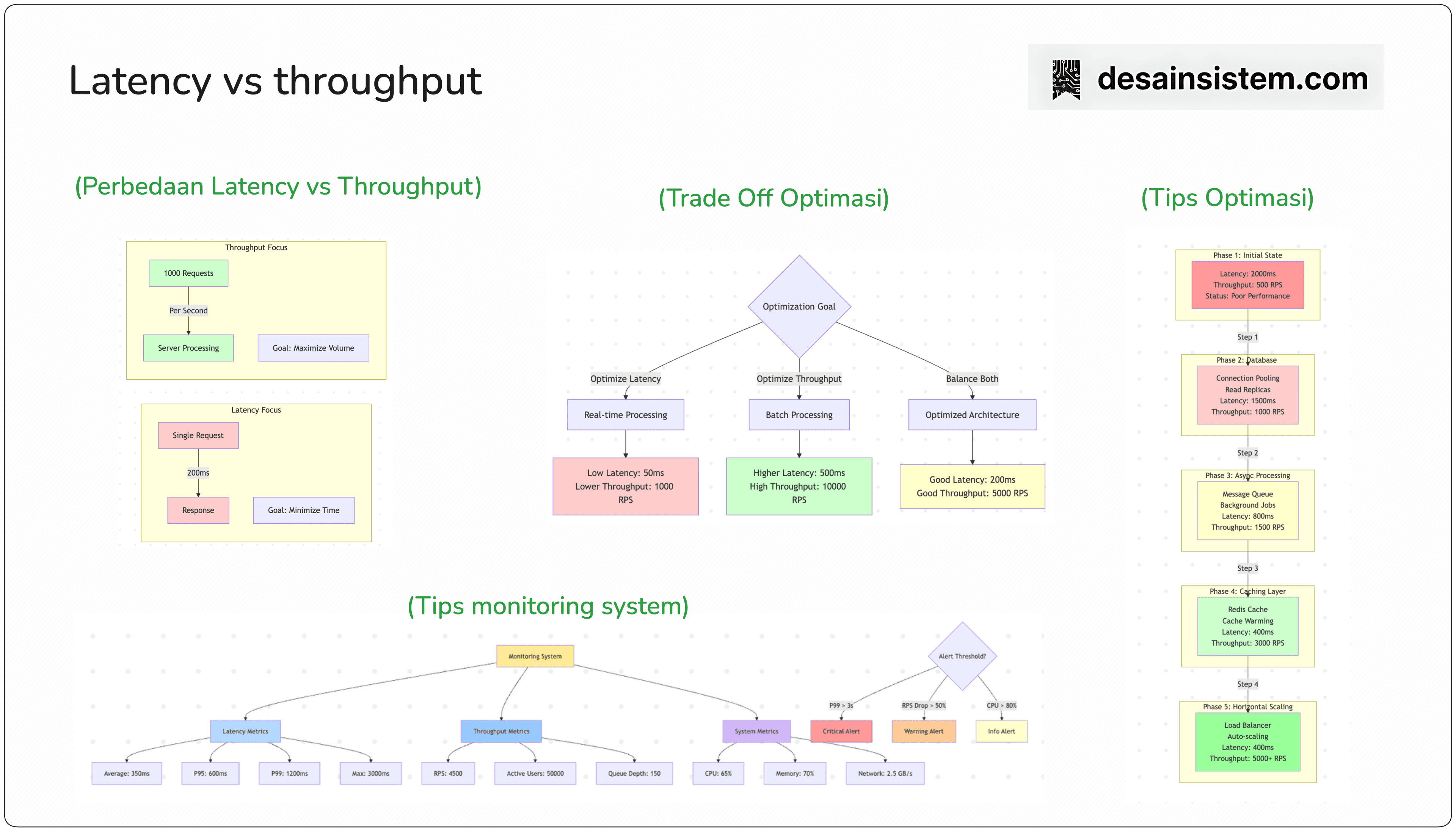
Availability atau ketersediaan adalah proporsi waktu di mana sistem beroperasi secara normal dan dapat diakses ketika dibutuhkan. Availability mengukur seberapa andal sistem dalam memberikan layanan kepada pengguna.
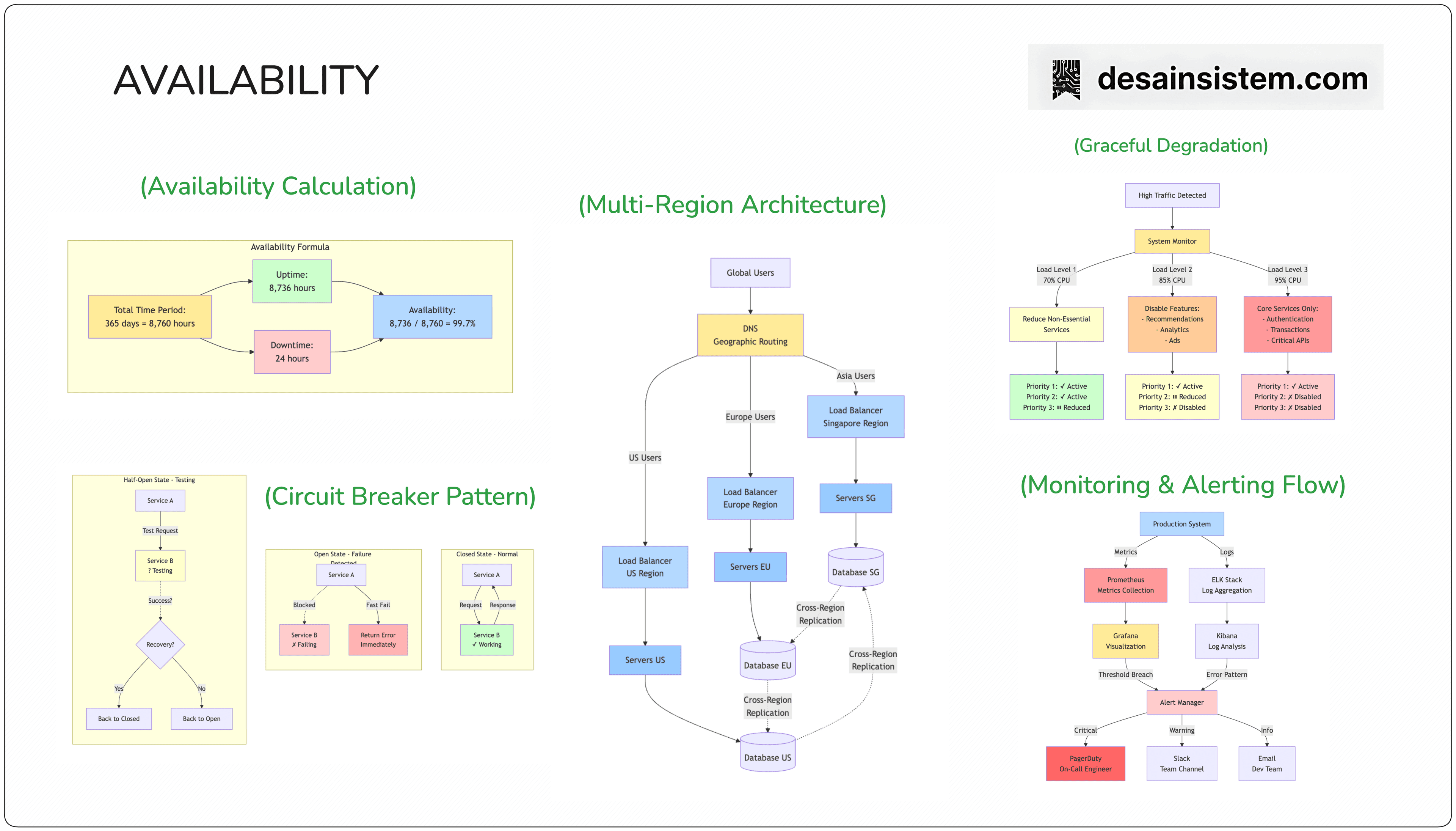
Availability dihitung dengan formula:
Availability = Uptime / (Uptime + Downtime)
Dimana:
Uptime: Periode waktu ketika sistem berfungsi dan dapat diakses
Downtime: Periode waktu ketika sistem tidak tersedia karena kegagalan, maintenance, atau masalah lainnya

Mengapa Availability Penting?
Downtime dapat berakibat fatal bagi bisnis:
Kehilangan revenue secara langsung
Kerusakan reputasi brand
Hilangnya kepercayaan pelanggan
Kerugian produktivitas
Potensi kehilangan pelanggan ke kompetitor
Contoh Dampak Downtime:
Amazon: Kehilangan $220.000 per menit downtime
Facebook: Kehilangan $90.000 per menit downtime
E-commerce lokal: Kehilangan ribuan transaksi selama peak hours
Availability Tiers (Tingkatan)
Industri menggunakan sistem "nines" untuk mengukur availability:
| Availability | Downtime per Tahun | Downtime per Bulan | Sebutan |
| 99% | 3.65 hari | 7.31 jam | Two nines |
| 99.9% | 8.76 jam | 43.83 menit | Three nines |
| 99.99% | 52.56 menit | 4.38 menit | Four nines |
| 99.999% | 5.26 menit | 26.30 detik | Five nines |
| 99.9999% | 31.56 detik | 2.63 detik | Six nines |
Target Availability Berdasarkan Industri:
E-commerce: Minimal 99.9% (Three nines)
Banking/Finance: 99.99% - 99.999% (Four to Five nines)
Healthcare: 99.99% - 99.999% (Four to Five nines)
Social Media: 99.9% - 99.99% (Three to Four nines)
Enterprise SaaS: 99.9% - 99.99% (Three to Four nines)
Komponen-komponen Availability
1. Reliability (Keandalan)
Kemampuan sistem untuk berfungsi dengan benar dalam kondisi tertentu selama periode waktu tertentu.
2. Fault Tolerance
Kemampuan sistem untuk tetap beroperasi meskipun ada komponen yang gagal.
3. Redundancy
Memiliki komponen cadangan yang dapat mengambil alih ketika komponen utama gagal.
4. Recoverability
Kemampuan sistem untuk pulih dengan cepat setelah terjadi kegagalan.
Strategi Meningkatkan Availability
1. Redundancy (Redundansi)
Memiliki backup untuk setiap komponen kritis.
Jenis-jenis Redundancy:
Active-Active: Semua server aktif menangani traffic
Active-Passive: Server backup standby sampai server utama gagal
N+1 Redundancy: N server untuk menangani load, +1 sebagai backup
2N Redundancy: Dua kali jumlah komponen yang dibutuhkan
2. Load Balancing
Mendistribusikan traffic ke multiple servers untuk mencegah overload.
3. Health Checks & Monitoring
Monitoring real-time untuk deteksi masalah sebelum berdampak pada pengguna.
4. Failover Mechanisms
Automatic switching ke backup system ketika komponen utama gagal.
5. Geographic Distribution
Mendistribusikan sistem ke multiple data centers di lokasi geografis berbeda.
6. Database Replication
Replikasi data ke multiple database servers.
(ini hanyalah contoh studi kasus saja, bisa jadi ini bukan kejadian aslinya)
Studi Kasus: Gojek
Latar Belakang
Gojek adalah super app yang menyediakan berbagai layanan dari transportasi, food delivery, hingga pembayaran digital. Dengan jutaan pengguna aktif harian dan ribuan driver partner, availability adalah hal yang sangat kritis. Downtime berarti driver tidak bisa menerima orderan dan pelanggan tidak bisa memesan layanan.
Tantangan Availability
Insiden Awal (2016-2017):
Aplikasi sering crash saat jam sibuk (7-9 pagi, 5-8 malam)
Driver kehilangan orderan karena sistem tidak responsif
Customer tidak bisa melakukan pembayaran
Downtime mencapai 2-3 jam per bulan (availability ~99.5%)
Dampak Bisnis:
Kehilangan revenue Rp 500 juta per jam downtime
Ribuan komplain di social media
Driver beralih ke kompetitor
Trust pelanggan menurun drastis
Solusi yang Diterapkan
1. Multi-Region Architecture
Gojek mendeploy infrastruktur di multiple availability zones dan regions:
Implementasi:
Primary Region: Jakarta (Google Cloud Asia-Southeast1)
Secondary Region: Singapore (Google Cloud Asia-Southeast2)
Tertiary Region: Australia (Google Cloud Australia-Southeast1)
Manfaat: Jika satu region down, traffic otomatis di-route ke region lain.

2. Database Replication Strategy
Implementasi database replication dengan multiple layers:
Master-Slave Replication:
Master DB (Jakarta)
├─> Slave 1 (Jakarta - Different Zone)
├─> Slave 2 (Singapore)
└─> Slave 3 (Australia)
Karakteristik:
Write operations ke Master
Read operations ke Slaves
Automatic failover jika Master down
Replication lag < 1 detik
3. Circuit Breaker Pattern
Implementasi circuit breaker untuk mencegah cascading failures:
Cara Kerja:
Monitor failure rate setiap service
Jika failure > 50% dalam 10 detik → Circuit OPEN
Request langsung return error tanpa hit service
Setelah 30 detik → Circuit HALF-OPEN
Test dengan beberapa request
Jika success → Circuit CLOSED (normal)
Hasil: Mencegah satu service yang bermasalah menjatuhkan seluruh sistem.

4. Comprehensive Monitoring
Implementasi monitoring system yang robust:
Tools yang Digunakan:
Prometheus: Untuk metrics collection
Grafana: Untuk visualization
PagerDuty: Untuk alerting dan on-call management
ELK Stack: Untuk log aggregation dan analysis
Metrics yang Dimonitor:
Response time per endpoint
Error rate per service
Database connection pool
CPU, memory, disk usage
Network latency
Request throughput
Alert Configuration:
- Response time > 500ms selama 2 menit → Warning
- Response time > 1000ms selama 1 menit → Critical
- Error rate > 1% → Warning
- Error rate > 5% → Critical
- CPU usage > 80% → Warning

5. Graceful Degradation
Implementasi graceful degradation untuk layanan non-critical:
Contoh Implementasi:
Ketika sistem overload, fitur recommendation dimatikan
Promo dan ads tidak ditampilkan
Historical data ditampilkan dari cache
Core function (booking, payment) tetap berjalan
Prioritas Service:
Priority 1 (Must Work): Order placement, Payment, Driver matching
Priority 2 (Important): Order tracking, Customer support
Priority 3 (Nice to Have): Recommendations, Ads, Analytics

6. Chaos Engineering
Gojek menerapkan chaos engineering untuk test system resilience: (https://www.gojek.io/blog/loki-our-chaos-engineering-tool-for-data-infrastructure-at-go-jek)
Praktik yang Dilakukan:
Randomly kill service instances di production
Simulate network latency
Simulate database failover
Inject errors secara random
Test backup & recovery procedures
Tool: Netflix Chaos Monkey

7. Rate Limiting & Throttling
Implementasi rate limiting untuk mencegah system overload:
Configuration:
API Rate Limits:
- Per User: 100 requests/minute
- Per IP: 500 requests/minute
- Per Service: 10,000 requests/second
Throttling Rules:
- Non-critical API: 50% bandwidth saat high load
- Background jobs: Pause saat CPU > 90%
8. Zero-Downtime Deployment
Implementasi blue-green deployment dan canary releases:
Blue-Green Deployment:
Deploy versi baru ke environment terpisah (Green)
Test di Green environment
Switch traffic dari Blue ke Green
Rollback instant jika ada masalah
Canary Release:
Deploy ke 5% traffic dulu
Monitor error rate dan performance
Gradually increase ke 100%
Automatic rollback jika error spike
Hasil Implementasi
Metrik Availability:
Sebelum: 99.5% availability (~3.65 jam downtime/bulan)
Sesudah: 99.95% availability (~21.6 menit downtime/bulan)
Target 2024: 99.99% availability (Four nines)
Metrik Teknis:
MTBF (Mean Time Between Failures): Meningkat dari 30 hari menjadi 180 hari
MTTR (Mean Time To Recovery): Turun dari 45 menit menjadi 5 menit
Incident Response Time: Turun dari 15 menit menjadi 2 menit
False Positive Alerts: Turun dari 40% menjadi 5%
Impact Bisnis:
Revenue loss karena downtime turun 85%
Customer satisfaction score meningkat dari 3.8 menjadi 4.6
Driver retention rate meningkat 25%
Cost of downtime turun dari Rp 1.5M/bulan menjadi Rp 200K/bulan
Jumlah incident critical turun dari 8/bulan menjadi 1/bulan
Pelajaran yang Dapat Diambil
Monitoring adalah Fundamental: Tidak bisa meningkatkan yang tidak diukur
Automate Everything: Manual intervention lambat dan error-prone
Plan for Failure: Assume setiap komponen akan gagal
Test in Production: Chaos engineering mengungkap masalah yang tidak terlihat
Gradual Rollout: Canary deployment mencegah large-scale failure
Prioritize Services: Tidak semua service harus always available
Fast Recovery > No Failure: Focus pada MTTR, bukan hanya prevent failure
Trade-offs dalam Availability
1. Availability vs Cost
Higher availability = Higher cost
Contoh:
99.9% availability → 1x cost
99.99% availability → 5-10x cost
99.999% availability → 50-100x cost
2. Availability vs Consistency
CAP Theorem: Tidak bisa achieve ketiganya (Consistency, Availability, Partition Tolerance) secara bersamaan.
Pilihan:
CP Systems: Prioritize Consistency over Availability (Banking)
AP Systems: Prioritize Availability over Consistency (Social Media)
3. Availability vs Complexity
System yang highly available cenderung lebih complex.
Balance yang Harus Dijaga:
Complexity → Harder to maintain
More components → More potential failures
Over-engineering → Waste resources
Calculating Availability
Formula Dasar
Availability = Uptime / (Uptime + Downtime) × 100%
Composite Availability
Untuk sistem dengan multiple components:
Serial Components (all must work):
Total Availability = A1 × A2 × A3 × ... × An
Example:
Load Balancer (99.9%) × App Server (99.9%) × Database (99.9%)
= 0.999 × 0.999 × 0.999
= 0.997 = 99.7%
Parallel Components (any can work):
Total Availability = 1 - [(1-A1) × (1-A2) × ... × (1-An)]
Example: 2 servers with 99% availability each
= 1 - [(1-0.99) × (1-0.99)]
= 1 - [0.01 × 0.01]
= 1 - 0.0001
= 0.9999 = 99.99%
SLA (Service Level Agreement)
Komponen SLA
SLI (Service Level Indicator): Metrics yang diukur
SLO (Service Level Objective): Target internal
SLA (Service Level Agreement): Kontrak dengan customer
Contoh:
SLI: API response time < 200ms
SLO: 99.9% of requests < 200ms (internal target)
SLA: 99.5% of requests < 200ms (customer guarantee)
Tools untuk Monitoring Availability
1. Uptime Monitoring
Pingdom
UptimeRobot
StatusCake
Site24x7
2. APM (Application Performance Monitoring)
New Relic
Datadog
Dynatrace
AppDynamics
3. Infrastructure Monitoring
Prometheus + Grafana
Nagios
Zabbix
CloudWatch (AWS)
4. Log Management
ELK Stack (Elasticsearch, Logstash, Kibana)
Splunk
Sumo Logic
Papertrail
Kesimpulan
Availability adalah aspek krusial dalam system design yang berdampak langsung pada user experience dan business revenue. Seperti yang ditunjukkan dalam studi kasus Gojek, pencapaian high availability memerlukan kombinasi dari:
Redundancy di semua layer
Monitoring yang comprehensive
Automated failover mechanisms
Geographic distribution
Chaos engineering untuk testing
Clear incident response procedures
Kunci sukses adalah memahami bahwa availability bukan hanya masalah teknis, tetapi juga business decision. Organisasi harus menentukan level availability yang sesuai dengan kebutuhan bisnis dan budget yang tersedia, kemudian secara konsisten maintain dan improve sistem untuk mencapai target tersebut.
Ingat: "Hope is not a strategy" - Selalu memiliki rencana untuk gagal dan membangun sistem yang dapat menghandle dan recover dari kegagalan tersebut